Semantic Java Web Application Demo
Wednesday, March 26, 2008
Abstract: this entry is about a semantic web application I created using Java, GWT, Semantic Hacker API, and Google Search API. You can find the running application at SemanticJournal.Semantic WebThere is quite a lot of data available on the web. The question now is what to do with all of it. We can index it, search it, social graph it, but all of it needs context. In the past, we (human users) have provided the context. What we need is for the machine to contextualize and organize it so that we don't waste our time searching for information: with our free time, we can do more productive things such as imagine the next wave of web technologies.
What's the solution? The
Semantic Web, of course. The problem is that it's taking a long time to really become the useful web extension everyone involved is promising it to be. Well, things are changing and companies with large amount of resources are beginning to let some of this new technologies reach the general public--by general public I mean us developers, and then we pass it down to users in the form of software applications.
So, what's the hold up? It's simple: contextualizing text, images, videos, or anything stored in a computer, is really hard if you don't have a human brain. Creating software to do any of this takes a lot of time and lot of know-how. Obviously, the larger software companies have more money to throw at the problem.
The AppWhile thinking of new things on what to spend my free time, I thought of coding something (after daily coding). And as luck would have it, yesterday, I found Semantic Hacker's API. This thing parses chunks of text and finds semantic themes within them. It works reasonably well, so I decided to give it a try and created an application that I've had in mind for a while now. It's called The Semantic Journal (and it's in beta, because it's the Web 2.0 thing to do).

The concept is simple: save journal entries and automatically search the web for related themes within the text. Creating an application that does this is rather complex, as it needs to be able to parse the text to understand what it is talking about, and then it needs to search the web for related content. All this needs to be done at the same time for it to be useful.
I already alluded to the difficulty of understanding text and finding useful information in the web. If I were to do it all from scratch (without any help or funding), it would take me years and I wouldn't get close to creating anything scalable. What's a small company of one to do? Use what's available out there.
This brings me to the architecture of the application. The GUI was created using Google's GWT framework. There is no particular reason for using GWT, except that it makes developing true AJAX application so easy. The contextual parsing was created using Semantic Hacker's API (I already explained how this works). And the web searching was created using Google's search API (I have already created an
application using this technology, so all the code is reused).
LimitationsEven though this is a great mash up of web services, there are limitations. On the one hand, I'm using freely available web services which will probably limit the commercial viability of any application I create. On the other hand, I'm at the mercy of the quality of the semantic engine and the search engine: if the makers of these two web services choose not to upgrade their free APIs, my applications will never get better. Neither of these limitations are a show stopper to develop useful applications, but it does mean that if you are using these free APIs you need to be aware that if the publishers change them you will need to refactor your code. Most important, though, you will need to develop a solid business model to live happily ever after.
The App DissectedI already pointed out the nifty Web 2.0 logo. Now lets talk about the functionality (I have highlighted the important parts for every image to follow). First, you need to type in the title and content of your entry.
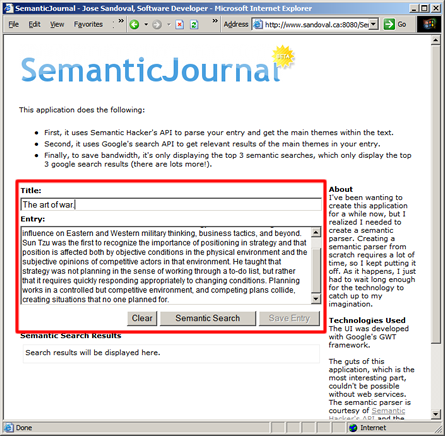
When you click the "Semantic Search" button, I send a service call through Semantic Hacker's API together with the text typed into the title and entry input fields. The API sends back an
XML result stream, which I then parse to get the top 3 themes (the API has a ranking mechanism).
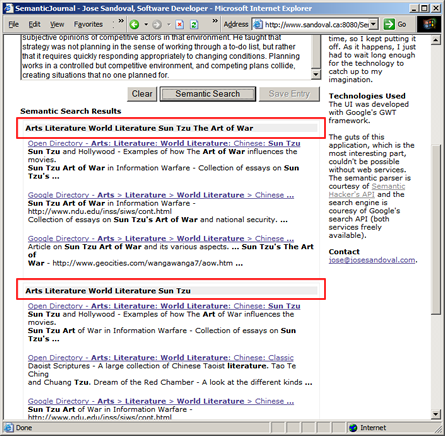
After I have these labels, I make asynchronous calls to google through their search API and get the top 3 results for that particular Semantic Signature
©. (Note that you can
no longer get a new key for this web service.)
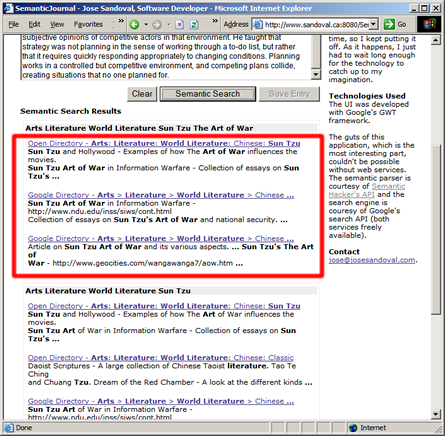
Again, the idea of this application is to allow the user to concentrate more on the thinking aspect of doing research and less on the mechanical steps of searching for resources.
For this iteration, I have opted to use buttons to make the user take actions; however, my ideal application would do everything in the background, without the user ever taking any direct action: a truly semantic web application. My limitations are tied to the limitations I talked about above: because I'm using free web services, I have a limited number of daily requests (too many on a single day, my application is down; not ideal for a commercial product).
The FutureThe future is bright for the semantic web. We just need the big guys to let us play with their data and supercomputers. These APIs are a start, but I want more.
What's the future for my semantic journal? I think it's a neat idea, but I need to spend some time to polish it and develop a solid business plan around it. I'm not even sure a business model can be developed, but if it does, it will have to be a vertical market--these type of applications are not everything to every one. I actually have one niche in mind, but you have to send me an email if you want to hear my idea.
AJAX under patent attack
Tuesday, March 25, 2008
The concept of a patent after-market is not new to me, but is not anything to brag about. There is something iffy about it, although it's completely legal. If you are the seller, you are in a position to make a lot of money, as you are more or less selling your technology. If you are the buyer, you are also in a position to profit from someone's innovation. No, not by commercializing it or creating new products but by licensing and enforcing your "new to you" intellectual rights.
The site Reg Developer has an
article discussing the sale of a patent that could include the AJAX technology we've all grown to love (or hate, depending on the use).
The concept of asynchronous server calls is apparently
patented. It's not specifically naming AJAX, as the AJAX moniker came after the filing's date, though it could be included. For the buyer, the payout is increased by the number of well known companies allegedly infringing on the IP. For example, Google, Microsoft, and Apple.
I'm not sure if the new owners would go after the little guy creating AJAX apps. I also wonder if the patent would be upheld in the courts. AJAX is not new, so it will be interesting to see if previous instances of the process specifically described in the patent were in use before 1999.
For now, however, I'm still safe with my demo AJAX
apps (I have more, but are on-going development contracts).
Imagine a world where you have to pay a license fee to use HTML? Sure, HTML and AJAX are not the same thing, but AJAX is a very powerful tool under the right circumstances and it is one of the Web 2.0 technologies (not ubiquitous as HTML, but necessary to create highly interactive browser apps).
I don't think the process or ability to execute asynchronous RPCs should be monetized. In other words, crippling developers will probably not be the noblest contribution to the web world. We'll see what happens next week.
The infamous interview. The video of Sarah Lacy's interview of Mark Zuckerberg
Monday, March 10, 2008
Some people out there think that this has been the worst interview in the history of interviews. I'm not sure it's the worst, but it is awkward at times.
Judge for yourself:
Mark Zuckerberg, Sarah Lacy Interview Video.
Mark is the face guy (also CEO) of Facebook; Sarah Lacy is a journalist from BusinessWeek.
Whether she likes it or not, Sarah Lacy has become the story, which is apparently bad if you are a
journalist, and the latest meme in the web world. I'm sure she'll benefit from the publicity, but it has to be an interesting experience to be singled out by a large number of
strangers.