RESTful Swing Client
Friday, March 27, 2009
Chapters 2 and 3 of my book cover RESTful Java clients. The term
RESTful Java client sounds fancier than it should be, as I
already posted a simple Java client that only requires about 5 lines of code to do everything. However, the value of web services is not connecting to them, but consuming the results--consuming results means doing something important with them.
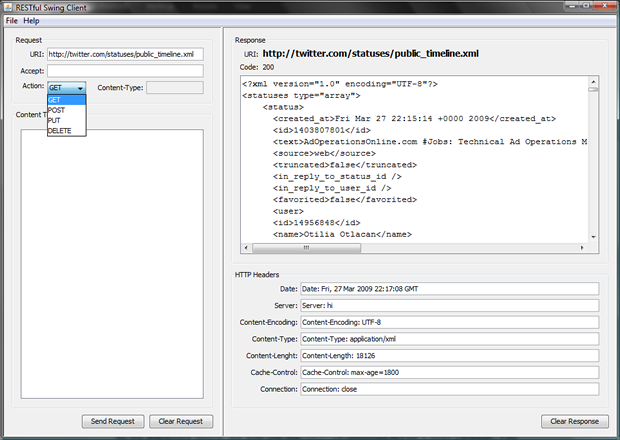
For the later chapters, I get into the design and implementation of fully RESTful web services. Because of this, I will need something to test the code. The something is part of Chapter 2, for which I have created a generic RESTful test client that connects to any service that has a URI. Consequently, this small application can connect to any HTTP server.
Once the book is published, I will make all the code available in this site. For now, I will leave you with the screen shot that is in the book:
Dangers of Wikipedia?
Wednesday, March 25, 2009
I was looking around my site's referrer list and found something interesting and disturbing. I found one of my pages linked from Wikipedia. The link in question is
Invention and Innovation: Microsoft's Photosynth.
This is the first time I've ever been linked from Wikipedia as a source for something. I have to admit that it's flattering; however, Wikipedia is
completely wrong by attributing the creation of PhotoSynth to me. I didn't create it; I just a wrote a short description of it on my site. I re-read the entry to make sure I didn't give the impression that I had anything to do with the project (I didn't and my entry doesn't imply it either), but whoever created the Wikipedia entry completely misunderstood my entry.
We've read the stories about libelous passages on politicians profiles, but I think this attribution is similar. I will fix the entry, but I'm not sure who added it to the wikipedia article.
The article is here:
Timeline of United States inventions and discoveries.
The citations is here:
Invention and Innovation: Microsoft's Photosynth.
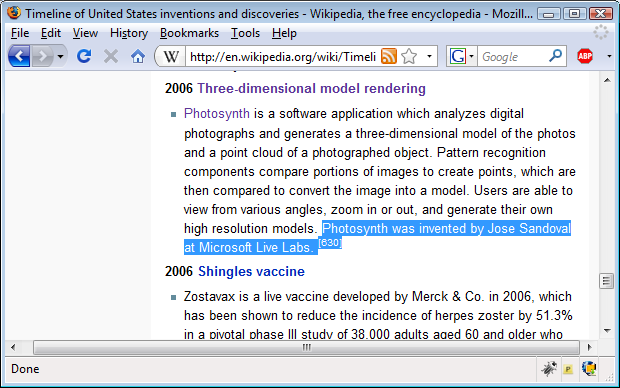
Again, the citation is completely wrong: I had nothing to do with that project.
Simple RESTful Java client and why Twitter's API is not a RESTful web service
Saturday, March 21, 2009
The clientThis is a RESTful Java client, and is as unadorned as you can get:
/*
* RESTClient.java - Mar 17, 2009
*
* Copyright (c) 2009 Jose Sandoval
*
* All rights reserved.
*/
package com.restfuljava.chapter2.command;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
public class RESTClient {
/**
* Connect to twitter REST API and get public messages.
*
* @param args
*/
public static void main(String[] args) {
try {
URL twitter = new URL("http://twitter.com/statuses/public_timeline.xml");
URLConnection tc = twitter.openConnection();
BufferedReader in = new BufferedReader(
new InputStreamReader(tc.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
System.out.println(line);
}
in.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
This app connects to Twitter's web service, and returns the latest stream of public updates. The result of this call (at 5:29 PM EDT) looks like:
<statuses type="array">
<status>
<created_at>Sat Mar 21 21:29:08 +0000 2009</created_at>
<id>1367587475</id>
<text>@SDMSTYLECEO hey girl I'm at this restaurant
boycotting eating this baby cow parmesan. Lmao</text>
<source><a href="http://orangatame.com/products/
twitterberry/">TwitterBerry</a></source>
<truncated>false</truncated>
<in_reply_to_status_id>
<in_reply_to_user_id>16535504</in_reply_to_user_id>
<favorited>false</favorited>
<user>
<id>19477616</id>
<name>J Starr</name>
<screen_name>whoisjstarr</screen_name>
<description> Editorial Director, Writer/ decision maker/
super dope chick who does lots of super dope things!
Swagger, Spandex, & Semicolons! Cheeah! </description>
<location>NY</location>
<profile_image_url>http://s3.amazonaws.com/
twitter_production/profile_images/104527501/
iheart_biggerme_normal.JPG</profile_image_url>
<url></url>
<protected>false</protected>
<followers_count>181</followers_count>
</user>
</in_reply_to_status_id>
...
</status>
</statuses>
Twitter's API is not a RESTful web serviceI should point out that Twitter's API is not a RESTful web service, because of a simple design choice. The issue is that the request type of a resource's representation is part of the URI and not the HTTP protocol's request method. In this case, we have a GET request method type, but we don't have an
Accept request field that tells the service what type of response to send back. The API returns a representation that depends on the URI itself, namely:
http://twitter.com/statuses/public_timeline.xml
If we change the
.xml part of the URI to
.json we get a JSON representation instead of an XML representation. Therefore, this is not a fully RESTful web service.
Of course, this is a design choice that makes coding RESTful clients easier: we simply connect to the URI and get a valid result. However, for a distributed application to be a RESTful web service, it must adhere to
all the constraints outlined by Fielding and not just some of them--he's very adamant about web services being called RESTful that are not RESTful because they don't strictly
adhere to all the constraints.
Should Twitter continue calling the API RESTful? I guess they can call it whatever they want, but, strictly speaking, their web service is not RESTful.
Should we care, if gets the job done? Well, yes and no: in this case, the API is useful and easy to use, but it's not properly labeled.
I think it's too late for Twitter to change the API, as there are a lot of apps that use the service as it is. In other words, adhering to all the REST guidelines is no longer an option. C'est la vie...
Labels: REST
Making Java client/server applications from standalone Java applications
Saturday, March 14, 2009
The benefits of client/server architectures are too many to list here, and going through them would detract from my main point: creating a Java distributed application from a standalone Java app that wasn't designed and coded to be one. In other words, having something that looks like this:
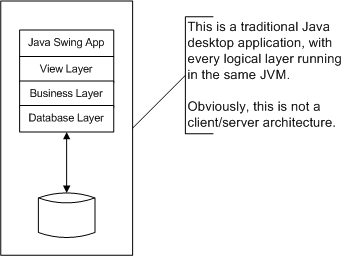
Look something like this:
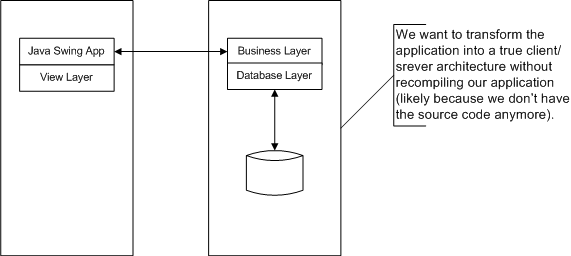
Creating a Java application from scratch that looks like the latter diagram is not hard, for example, we can use RMI calls to exchange messages between the layers; we could use the notion of a
web service to exchange messages between each running program; or we could create our own TCP/IP client and server to exchange objects between both JVM instances.
On the other hand, making a distributed application from a compiled app with no source code seems almost impossible, or can get very complex if done by hand. Nevertheless,
j-orchestra can do it for us in no time and, more important, without writing a single line of code. Give it a try...
Do we need HTML 5?
Tuesday, March 10, 2009
As far a traditional web applications go, HTML 4 has served remarkably well. We've been able to create countless database driven applications, and, once we understood how to use Ajax calls, we began to create highly interactive applications. So why is
HTML 5 needed?
The claim is that good application will become
better. But it all depends on your application. A typical CRUD-style application doesn't really need the cherished CANVAS HTML element. We can do without it, as typical data representation is most useful in tabular form. On the other hand, having the CANVAS element uniformly available in all browsers will make things easier for web developers, since we don't have to create convoluted logic to account for IE's lack of cooperation.
Where is CANVAS needed? Mostly on graphic heavy apps, which require detailed pixel control. Will it replace Flash? Some of it. But I think Flash developers out there are already evolving with the times: pure JavaScript libraries and DHTML can already do most of what flash was used for. So, it's becoming clear that the browser will provide most of what's required off-the-box and won't need heavy plug-ins to do flashy stuff.
By the way, any incremental enhancement to any technology is a welcomed change. As long as all browser providers play by the rules, HTML 5 will be a great upgrade.
If you are from the future, watch this movie...
This is a great low-budget Sci-Fi film. I don't want to say too much, but if you are a kind of an entrepreneur or a garage tinkerer, you'll really enjoy it. Finally, if you know a bit of Physics, you'll find the dialog quite realistic; I mean that you won't cringe at every turn because they said something incredibly dumb (they say dumb things in a very believable way--yes, there is a difference).
Silly charts, but accurate charts...
Monday, March 09, 2009


Do we know everything?
Sunday, March 08, 2009
We've reached a point in human history where we know everything. Or we think we know everything, thanks to google and iPhones or whatever smart phone you have.
Try this experiment. Say you want to know the population of Albatrosses in Argentina. This is a very useless bit of information, and it's esoteric enough for not just anyone to have lingering on the tip of the tongue. Depending on where you are, someone will know the answer. However, you could just google it and get a reasonable approximation (or the exact number).
Because we know everything, we are also becoming smarter. What I mean is that we know everything that a collective mind is able to know, write down (on blogs, for example), and quickly find with tools like search engines. Of course, not all the information is true or useful or both, but if you take the average of our collective wisdom we are very smart--but only if we have google in front of us.
I must qualify what
everything means here. By everything, I don't mean everything everything. I mean everything to a reasonable degree. If you were to ask what the meaning of life is, our collective wisdom doesn't have the answer. We have crazy concepts, but none of them are verifiable. What's more, there are things that we just don't know yet and will likely never know. Have you heard of Gödel's incompleteness theorem? If you haven't, you can google it, and then know--which is my point exactly. Go ahead
google it...I'll wait.
If you are back, then you'll agree with me now that not everything is provable. And if not everything is provable that means that we are likely to not know everything everything (ever). But we know enough I guess, thanks to search engines and our quick thumbs.
I will not venture to take sides and proclaim that this is a good thing or a bad thing. All I can say is that it just is, and that we're becoming quite a uniform bunch of thinkers: we get the same answers that everyone one gets, because of the relevance on search results--now, this could be argued to be a very bad thing.
But haven't we been here before? I think we have--to a certain extent. The era I'm referring to was part of the whole printing press revolution.
There is a big difference, however; blogs and web sites are not to be trusted. Sure, some are good, but the majority of blogs are crap and are just trying to get us to buy crap. With the printing press revolution, on the other hand, there was a sense of standards that needed to apply to anything published: it was relatively expensive to print a whole book, then it had to be of a reasonable quality. The same can't be said for blogs: we have zero barriers of entry and anyone can write anything (this entry is proof in point).
So, knowing more is not in itself that bad, right? Look at all that we've accomplished before and after the dark ages. What's bad, I contend, is the consensus building that comes from having all the information available in seconds.
Again, getting the information so quickly is not bad at all. The issues is that we get someone else to make up our minds for us. Blogs are full of bias and they are only representing a distilled view of whatever topic we are looking for. Therefore, if search engines keep giving us the most "relevant" result for a topic, then that will become the answer from now on. It's group-think at a massive scale.
Why didn't this happen with printed books? It did, in a way. But I go back to the quality. What's more, with books it took a little longer to find what we were looking for, and we could have bumped into a counter example of what we thought was right, thus giving us a chance to evaluate a couple of alternatives before making up our mind.
To be fair, we could do the same with search results. However, the first result is likely the only thing we will evaluate and then make up our mind about it--I mean, who has time to keep searching? It's how memes get created. Memes in the era of the web and social networking are likely to be half-truths and eventually become crowd-wisdom.
I was wrong about Ronaldo
Thursday, March 05, 2009
Last year Ronaldo injured himself during a game in Italy. I said that he was unlikely to play again, but I was wrong: he's
playing for Corinthians, in Brazil.
I hope he can last a little longer: he's a good player and a top scorer.
Microsoft can do some really cool stuff
Sunday, March 01, 2009
From time to time, Microsoft creates really cool
stuff movies. Check out this latest envisioning video:

The digital wallet is my favorite part.
I have to wonder, though, why in Microsoft's future world everything has an iPhone's user interface. "Look Mom, no keyboard."