Real Life
Wednesday, January 24, 2007
I think this web site is pure genious:
www.wefeelfine.org.
It's like real-life-writing at real-time speed. Similar to a time-machine that travels into the future but only works at regular speed. Yes, today is yesterday's tomorrow.
Ontario, Leave Calculus Alone II
Monday, January 22, 2007
I rarely sign petitions, but this one I think is worth while.
Save Ontario Calculus.
Why do I care that my son studies Calculus in high school?
I gave quite a few reason in
the past. My objections to the curriculum change were many and a bit ranty, but I really do care that my son will be at a disadvantage if he doesn't learn to differentiate and integrate before he gets to University.
I benefited it from high school Calculus (like many others), why take it away from younger Ontarians: it will only hurt them.
Institute for Avanced Personhood
Monday, January 15, 2007
Patient: "This bottle [of water] is too large."
Doctor: "Is it? Or are your expectations too small?"


Demetri Martin is one funny guy and he is very web savvy:
clearification. Free content. Well kind of: guess who is his sponsor?
Why the Network Effect Matters
Wednesday, January 10, 2007
A couple weeks before the end of 2006, I had a few tests done for my yearly visit to the Dr. It takes a few days for the results to be completed, then results are "sent" to the Dr.'s office.
Because of the way the Ontario health care system works (Universal Health Care), patients can get tests done in different lab companies regardless of the costs of the tests. As a patient, I go in, give my health card and get the tests done. No, the test are not free: my taxes pay for it. My point is that there is no product differentiation and there is no price competition.
These companies are government created oligopolies, in other words, they have been given the power to offer services based on different criteria that I don't know about.
Life is good in this industry since there are always sick (and healthy) people that need tests done and because there is no product differentiation, it is likely patients go to the most convenient location: the closest one. So having geographical dispersed labs on densely populated areas is a very good business strategy.
At least this is what I thought.
I found out that one of these lab companies is directly linked with my Dr.'s office, hence, results are immediately "uploaded" when they are complete (in quotes, because I don't really know how they upload the results). My Dr. likes this service so much that she actually suggested (she said preferred) that I use a particular company instead of the one I used (the one with no direct link to her office). With the other company, test results are either snail-mailed of faxed, and this becomes a problem when the paper results get lost.
This happened to me last week while on my follow up appointment: no one could find my test results, so I had to wait an extra 20 minutes for the lab to fax them again.
I'm sure the lab had already sent them and somewhere along the line someone lost the results. This is in itself an operational issue, but it is not the main problem--we loose paper all the time--the main problem is the inefficiency of storing thousands of results for thousands of patients in paper form.
The ideal solution would be to store them electronically in one location and have them available on computer screens throughout the building, i.e., results are searchable and available in seconds.
Of the two lab companies that I know of, only one has made it their business to solve this particular problem (the "lots of paper for a lot of customers" one). This very fact has given one of them a competitive advantage. The word "advantage" may sound out of place in a government created industry, as they will get paid for services rendered regardless. However, if patients go to one lab instead of the other at Dr.'s orders, then revenues will definitely have an effect for both companies. This is a zero sum game, really, if patients don't go to one lab they will go to the other one.
So competition doesn't only happen in pricing wars, or marketing campaigns (these companies don't advertise), or the obvious market competing arenas (customers, et al). These labs are competing in convenience, and it is not patient convenience directly but my Dr.'s convenience. Moral of the story: know thy customer.
I really can't say why only one particular lab has this implementation (it seems such a simple thing to do now a days: connect computers over the internet) but I can tell you that in the future I will be using the company that emails test results to my Dr., even if I have to drive an extra 5 minutes. I rather waste 5 minutes driving to the nearest location than waste 20 minutes sitting down in an empty, cold office waiting for results to be faxed again and hearing my Dr. and nurse repeating every time they come into the room that "[I] should have used the other lab company."
What is the network effect?
The most successful example of the network effect I can think of is the telephone. Having a telephone is only useful if a large number of people you know have telephones. Obviously, without one you can't call them and so the theory goes that if I have a telephone and tell you about all its marvellous qualities, it is likely you will also want a telephone and in turn you will tell all your friends and they will all get telephones. In a very short time, we all are on the phone discussing the deep secrets of the universe, or how cute our puppies look with that red, gag sweater--whichever is more important at the time.
It seems to be a very simple concepts, and if a product can in fact solve a problem for many companies (or individuals as the case for the phone) then this "networked" distribution can be used as a form of competitive advantage.
For my sake, let me define competitive advantage: it is that "something" that allows a business to earn above average profits in any industry. For example, if the average profit in a particular industry is 15% and your company is earning 17% (with a reasonable standard deviation), this is not competitive advantage. However, if the average profit is still 15% and your company is able to generate 30% profits in the same industry, then and only then you have a clear competitive advantage over your competitors. Likely with this profit margins your company will drive other companies out of business as you have likely decreased the cost of production to such a low level that competitors are not able to match you costs. In some instances, a company with relatively low costs of production will essentially become a monopolists.
Here is where my observation comes in: even in this type of government oligopoly (or duopoly, as I've only seen two companies doing this), companies need to be on their toes and always be looking for that extra edge to stay competitive. In fact, I am predicting that one of this companies will likely go out of business if it doesn't change its current strategy. And likely the one that doesn't connect to Drs. offices.
Michael Porter wrote in his essay "What is Strategy?" for the November 1996 issue of Harvard Business Review magazine that "strategy is the creation of a unique and valuable position, involving different set of activities." It is clear from this simple statement and my ramblings above what the activity for this particular example is--electronically make results available to Drs. However, not everything is lost for the competition as this particular "edge" gained currently can be quite easily copied.
And so the gears of commerce turn and turn and competition continues. The question is, how long will it take for every lab company in the province (or country) to connect to Drs. offices?
Sorting tables with Java
Tuesday, January 09, 2007
One of the main functions of computer applications is the visualization of data. The most common visualization format is a table with rows and column.
I find that the most desirable function in a table is that of sorting by specific column types. Whether sorting alphanumerically, dates, or object types, it helps the user find the information faster.
Not all data needs sorting, though. For example, sorting the following is not really needed:
| Name | Age |
| Jose | 145 |
| Gaius Julius Caesar | 2106 |
(This is such a silly example as we rarely encounter so little data to analyze.)
The solution to this almost trivial problem depends on how the system has actually being designed: what is the architecture of the system.
After looking back at the sorting algorithms I've used in the past, I started thinking of the different ways table sorting can actually be implemented.
Every case I present here does the same thing (sort a table), however, each case deals with the actual system at hand differently. In other words, the solutions presented are part of an existing web framework.
Note that there is nothing really earth shattering or new about any of these solutions. I just thought they would make a good example of different web architectures, and simple curiosity for some, for an almost trivial but necessary requirement in most web applications: sorting by column type.
(Click on the sequence diagrams to enlarge.)
Client Only Solution (DOM-JavaScript)The client only solution makes use of JavaScript and DOM to do all the sorting.
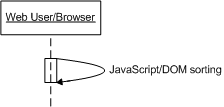
This is quite an easy solution to implement, as all the data is in the rendered HTML and sorting is accomplished via JavaScript, DOM, and CSS--of course, the data is stored in a DB, but I didn't include it in the diagram for simplicity's sake.
Matt Kruse has a very neat implementation of this and is available as a (free) JavaScript library. I won't steal his thunder, so go the
examples page to see the versatility of his solution.
The issue with a client only sorting implementation is that the data set can change on the database at any time and if we don't refresh the page with the new data important decisions could be made with incomplete information. Hence, in theory, every sorting request should check for new data and just keep sorting away.
Note, however, that if a table is part of a summary, for example, monthly income reports, then it is safe to use the JavaScript sorting as is--no need for data refresh.
But what about when the data needs to be refreshed for every sort request?
The simple act of sorting can put quite a load on resources if we have thousands of users doing the same thing at the same time and if every sorting action means a trip to the whole system. Therefore, any solution needs to take into account how it will behave under heavy load in the existing architecture.
As end users, we only care that our applications work. We don't want to know how complex, or simple the solution is. All we want to see is our tables sorting instantaneously. Hence, I present a few solutions (some better than others).
Case 1Go directly from the web page to the database and use SQL to return the sorted items (essentially, using "ORDER BY").
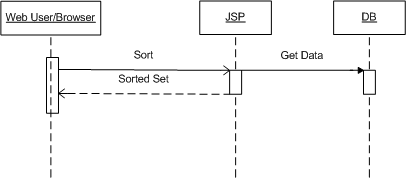
This is how web application were coded circa 1996: C or Perl application used to talk directly to databases. We still find this development pattern being implemented with newer scripting languages like PHP or Ruby.
Case 2Add a middle tier to handle the business requirements of your application.
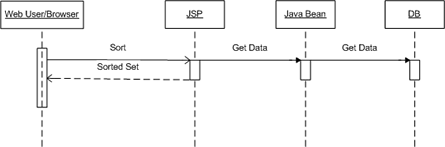
This is preferable to Case 1 above, however, it is probably not the most scalable solution. Nothing surprising here. All that has been done differently is that I've moved the logic embedded in the web page (JSP) into some middle tier, which is still part of the Web layer.
In this realm, you can find MTS/COM+ components with ASP pages and Servlet with JSP interaction, where you have massive middle tier servers doing all the work, i.e., concurrency, load handling, etc.
Case 3This is a typical MVC pattern implementation.
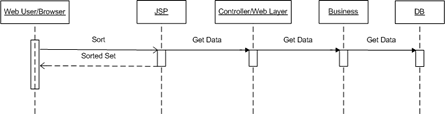
This way of doing things just separates code into logical chunks to do stuff. Even though it is a full MVC pattern solution, is not a very smart one. Every time sorting needs to be done, the whole system needs to be put into action--could be expensive with thousands of concurrent users.
Note that this is an advantage over the case 1 and 2, as I'm not coupling data to my actual business logic. And this separation is what leads to scalability of Software Development: you can have teams of 50 or 100 developers to work on the same code tree without any worries of duplicate or lost work.
Case 4Still and MVC solution, with some minor caching added.
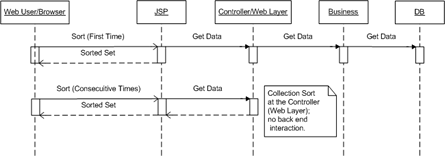
What I mean by caching is that for every sorting request the set is sorted in some web layer object. In Java, the data set can be stored in a collection object in the HttpSession.
I think you can see how sorting at the Web layer would be much more efficient when thousands of users are hitting the same server, i.e., the ball stops at the Controller layer and business and DB objects are not doing any of the work.
Case 5Now the bleeding edge solution (meant to be funny).
I did say that if your data set needs to be updated for every sorting request (you always need the latest data), then you can use Case 3 (use the whole system to sort by column). However, there is a better solution that makes use of Matt's JavaScript sorting library and an AJAX call.
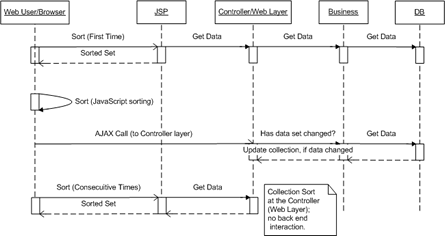
This is what is happening and why this is more efficient than Case 3 or 4:
- The first time the table is displayed, there are no two ways about it, you must hit the DB to get the data set.
- Once the data is rendered, you can serve every sorting request with the JavaScript library (no back end interaction means fast execution and no server load).
Now, what if the data changed on the back end after the first request and you need to have the latest data set at all times?
- This is where a bit of AJAX can be used if you don't want your users to keep refreshing the web page, i.e., Case 3 or 4.
You can make an asynchronous call to check if the data set has changed or not. And if it has, update the collection at the web layer. This will guarantee that the next time the table is sorted, fresh new data will be available. Once the fresh data has been rendered, then the JavaScript sorting code takes over and everything is quite fast again.
Note that the JavaScript sorting action needs to "know" that the collection at the web layer has been updated, and hence go to the controller to get the latest data set. I'm not sure if this step is clear in the sequence diagram, as I didn't want to combine the JavaScript sorting with the checking of the web layer for the data in the diagram, but these two actions must be coded as one. Also note that every asynchronous call (the AJAX part) does hit the backend at some pre-defined interval, however, to your user the interactivity of the application has improved, giving them an almost desktop feel to the web application.
SummaryAny solution presented here would end up sorting tables by column, however, each one is different depending on the architecture of the solution and the specific user requirement.
Case 5 is a combination of solutions and may seem a bit over done with so many layers doing stuff. However, if the requirement is part of an existing architecture, we must code to accommodate the design, i.e., the architecture is there for a reason, whether is to take advantage of load balancing or logical layering services.
Draft Entries
Sunday, January 07, 2007
This is a list of all the draft blog entries I accumulated in the last two years.
The majority of the entries are actually completed, however, after some editing, I don't like what I wrote or I feel the entry doesn't belong in my blog, which is mainly a technology and, to some extent, business blog.
I'm hoping to make some time to complete them to the point that I feel they deserved the be published.
My favourite unpublished entry is "Unlearning," which I apparently wrote quite some time ago and is part of my original philosophy of how we get know what we learn (to give you a taste of it: we don't learn, we remember).
One of the better aspects of reading is the ability to use one's imagination to fill in the blanks. Using your imagination, which of the following unpublished entries is your your favourite?
Why the Network Effect Matters 1/4/07
Gonzo blogging 12/26/06
Sorting tables 12/25/06
The Sport of Kings 12/24/06
The stock picker 12/19/06
Movie Theatre Exorcism Needed 12/11/06
Because we have a central bank 10/20/06
> 1 dimension 9/11/06
Adoration of the Magi 9/2/06
Marketing and Client Acquisition Methodology 8/17/06
Virtual CD-ROM 8/8/06
Confession of a drive through idiot 6/2/06
Improving the Software Engineering Process 5/19/06
Short Final Notes: Blogging is popular for many reasons 3/26/06
I feel sorry for James Frey, however, he made his bed but he must be sleeping in it 2/1/06
Writer not editor 11/17/05
Unlearning 7/8/05
Virtual CD-ROM in XP
Saturday, January 06, 2007
I have a portable computer that doesn't have CD-ROM drive. It weights around 2.5 to 3 lbs. Because of the convenient small size, I had to compromise with not having a CD-ROM drive. I rarely need one now a days, as most software is actually available to download online. But once in a while, some programs need the CD-ROM to function, even after the full install (I hate those programs).
So what can you do if you need a CD-ROM drive?
Fake it. I don't mean imagine a CD-ROM and fake using it, I mean fake the CD-ROM drive. In other words, use a virtual CD-ROM.
I didn't know that in XP you can create a virtual CD-ROM, using a handy Microsoft program called
Virtual CD-ROM Control Panel, until I needed one.
This tool doesn't come standard with any OS installation and it doesn't have any support, so you have to download it and play around with it to learn how to use it.
So if you have an ISO image of a CD and need to run it on your non-CD-ROM computer, this is the way to go. It works flawlessly.