The myspace.com appeal
Thursday, March 30, 2006
The internet has turned into an ubiquitous communication medium, and it has become more obvious to me that the sustainability of a web presence is all about web social communities and organic traffic growth.
This fact was not lost to a few entrepreneurial companies out there, for example flickr.com, technorati.com, friendster.com, del.icio.us, and digg.com all use the organic nature of the internet to their advantage. These businesses appear to thrive because of users' willingness to gravitate around their services. Though, I am not sure how profitable they are, they do have quite a large number of users (I count myself among them).
It seems odd to think of such a solitary activity as typing on a keyboard and staring into a computer screen to have anything to do with community building, but there is no other way to describe it.
We, as individuals, have such diversed interests that we are bound to find someone who has written something about any particular topic we are looking for. This traffic eventually evolves into trends, which in turn becomes a web community. In other words, "we search, we find, we stick around."
For example, it is likely you will read one or two other of my entries, and if you find anything remotely interesting you will probably bookmark my site or subscribe to it via RSS feeds. Just because you do this, it does not mean that what I have written is of an extremely important nature, on the contrary. But we are web surfers and this is the nature of the business: we are just curious to see what anyone else has to say about anything, without prejudice or personal interaction--perhaps an email here and there, but that is as personal as it gets.
This new type of computer usage can be confusing to some of us. I, personally, still find the appeal of web communities, such as myspace.com, perplexing. The whole community of myspace.com is about nothing and everything, at the same time. Anyone who is any body is a part of it. The voyeuristic flavour of the site still irks me a bit because so many people (of all ages) willingly share so much personal information about their mundane lives.
As a technology professional, I am not a afraid of change or uncertainty. On the contrary, I embrace the state of flux. So, it is my duty to at least try to understand how these web communities work and how people use them. Thus, in the spirit of research, I finally created a myspace account. My space in myspace.com is
www.myspace.com/d_atlacatl.
Being new to the myspace.com experience, I was surprised to find that within 1 minute of creating my site I already had a friend. Yes, a web friend. I have no idea who he personally is, but
Tom is my myspace.com friend.
I spent a couple of hours looking around the networks of people each "friend" creates. It is fascinating. And the more I looked around, the more I wanted to be quirky and unique, so updating "my space" became priority one.
I have to admit that I already put too much constructive energy maintaining this site, so keeping up with another, specially where you really have to become part of the community, is just not realistic. I still prefer the old style of rambling about for the sake of rambling and not expect to be linked by other interesting net citizens. Although, I would like to find out if "I am hot or not."
In other words, I have no altruistic motive to share my feelings with anyone, really, but just knowing that there are thousands of creative individuals centered around one web address is motive enough to sign up. I just have this feeling that there are hundreds of software applications and business models that are and will be spurting out of this community. Some will be useless and do not really deserve to be called software applications, but some will be worthy of venture money and from these we will keep learning how these internet protocols can be used for--aside from advertising, commercial web services, and complex banking and trading systems.
What type of innovations can we expect? Well, every kind. myspace.com knows that they can not provide every tool needed. They provide, however, the hardware, the bandwidth, and publishing tools to create and maintain hundreds of thousands of users. The rest, the true evolution comes from the users themselves, i.e., if someone needs something, this someone will just invent it and share the result with everyone around. This may not seem like much, but there have been cases where we have been surprised with this quiet, unfunded inventions, i.e., Napster.
Napter is the poster child for innovation where no one was looking to innovate. Shawn Fanning, a righteous dude, has written himself into the history books simply because he wanted to share his music with friends. There was no software available to do it, so he skipped a few computer science classes and designed and implemented a whole new music distribution medium.
The legality of the scheme came into question, and of course we all know what happened. The usage of the idea and program became illegal, but the beauty and simplicity of the peer to peer model still prevails and is evolving daily.
This revolution created new economies where there were none at all. Just in my last engagement at Sybase, I worked with the FIX Protocol implementing and enhancing applications that were described as follows:
SWIFTNet and GlobalFIX are the P2P (peer to peer) infrastructure of secured trade-related messages for banks, broker-dealers, exchanges, industry utilities and associations, institutional investors, and information technology providers from around the world.
It is P2P for real businesses where billions of dollars are transferred via the internet. Is sounds important, does it not?
So, how do I manage my web community around my web site? I do not, as I do not believe I have one. But if I did, I would just let it grow organically and randomly--no point in forcing traffic my way.
However, I do receive a few
hits per day. The main attraction, so far, seems to be my
resume and a quick
AJAX (XMLHttpRequest) example/tutorial I wrote last year. I think, overall, my blog entries are secondary, even though the main theme is technology, Java, and Software Engineering. But then again, how many of these blogs are out there? Why is mine so special? It is not, really, but I said there are so many web surfers out there and search engines are getting really good at indexing web content that some people will stumble upon my web address.
So my web community is mediocre at best, and none existing at worst. Unless you count a community of one, i.e., I read my own blog entries and, sometimes, I amuse myself. So, in this particular scenario, a man can indeed be an island, a web island.
For now, though, I will continue to be a web hermit and just live around the edges of this new type of society--no offence myspace.com, but be sure I will return to thee when I get rid of my fear of posting personal information or figure out why you exist.
Google pages review and tutorial
Wednesday, March 29, 2006
To navigate the google pages tutorial, click on the "Next" and "Back" buttons located at the bottom right hand corner.
Looking back at my entries, there are quite a few of them mentioning google. It is not really my fault. It is just that google releases so many web application and anyone writing about anything related to technology has to touch on the "g" subject once in a while.
This time around, it is pages.google.com. It is still a "by invitation" service only, but I managed to get an account with the service.
After playing around with it, I created a Flash
google pages tutorial. (Some of you do not like flash, so there is also an
HTML version.)
My thoughts on the service:
- It is not the first time this type of thing has been done. Anyone remember geocities?
- Google sure knows how to use AJAX.
- For anyone wanting to create a web presence, it is the way to go for a couple of reasons:
- Any web site created has google servers behind it, i.e., likely to be on 24/7/365.
- It is very easy to use and it gives you access to a few templates (they call them "looks").
- I think google will start deploying little tools here and there; I also think they will manage web domains for some sort of fee (currently, you only get a subdomain. For example, my web page is jose.sandoval.googlepages.com).
- Most people create web sites to blog, and google owns blogger...and AdSense...and Analytics...And google Talk...
It really does not take any deep insight to see how all these services will be tied together.
- I think google will have to add a payment scheme, in order to make small business use this type of service.
- The most appealing aspect, aside from no coding expertise required, it is FREE--you cannot beat the price.
How much is my writing worth? An AdSense profit ratio analysis of sorts
Tuesday, March 28, 2006
Before you read on, let me tell you what this entry is all about so that you do not waste your time: this entry is about analyzing the relationship between my web site's access log, google's AdSense reports, the number of published blog entries, and google's AdSense revenues; I have also calculated how much each word in my blog is approximately worth to advertisers.
(Even though I only analyze my web site results, the conclusions reached can probably be generalized to most blogs.)
Google's AdSenseIn the past, companies tried to figure out the online advertisement business, however, not many were successful exploiting the new web medium. It took a company like google to lay the groundwork for a successful online advertising model where all parties involved benefit. (To be fair, google did not invent the AdSense model. They actually bought a company that had the AdSense model already figured out, though they did have enough foresight and clout to make it part of the web vernacular.)
AdSense works as follows (well, this is my interpretation of its functioning): advertisers buy ads to be displayed in publishers' sites for a price, based on keywords that are related to the content of the web pages; when web surfers click on the ads, advertisers' accounts get charged and google makes money, which then splits the profits with the publishers. The price per click varies depending on the web site and how the context of the ad within the content of the web site is rated. In other words, not all clicks are created equal (more on this when I get to the analysis).
The AnalysisGoogle provides up to the hour reports of publishers' earnings, however there is no way to tell how much each keyword is worth to advertisers (or which keyword is the one attached to content).
Because you can only get rough averages from google's reports, I collected 3 separate sets of raw data spanning exactly 31 days from 3 different servers to run my own analysis and figure out how much each word I write in my blog entries is worth to advertisers.
Although I can only calculate estimates, this exercise does provide a good understanding of how everything works and sheds light into the question if it is worth while for any blogger to use this type of advertising program.
With a few keystrokes in a calculator, I found the following statistics:
| Total Days for analysis: | 31 |
| Total Page Requests: | 41,293 |
| Total Page Requests with google ads: | 5,484 |
| Total Blog Entries | 5 |
| Total Words for all Entries: | 4,538 |
| Total Clicks: | 52 |
| Total Earnings: | $12.17 |
With a bit more effort, I can get more detailed information:
| Earnings per Word (all pages): | $0.002681798 |
| Earnings per Blog Entry: | $2.434 |
| Earnings per Day: | $0.392580645 |
| Clicks per Day: | 1.677419355 |
| Page with ad/Total Requests: | 0.132807013 |
For a more sophisticated analysis, I took the 31 days worth of traffic, clicks per ad, revenue generated, and blog entries to generate charts and summarize the results.
Charting these items allowed me to see which entry generated the most clicks per ad and how new content generates more traffic (this assumption has a few caveats that I will explain later).
In order of published date, from left to right, the blog entries were:
Pyramidal Paradigms (February 23, 2006)
Code reviewer == Code editor? (March 5, 2006)
The lost civilization of our past was not Atlantis (March 9, 2006)
Football - Soccer - Futbol (March 13, 2006)
How to lose market share (the Sony way) (March 21, 2006)
Efficient Financial Markets and Google Application (March 21, 2006)
Page Requests vs. Blog Entries Analysis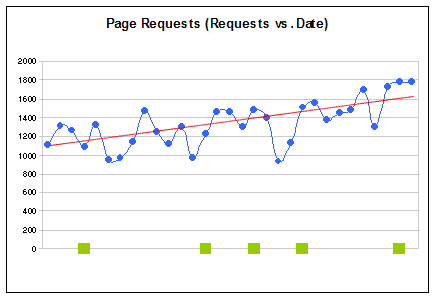
- Page requests increased throughout the period.
- There was total number of request of 41,293, with 13% of the total being from all blog entries (100+ in total, however, only the latest 5 were included for this analysis; also, only blog entry pages have google ads embedded within them).
- After the second entry, there was a noticeable increase in traffic.
Note that there are 3 entries separated by 3 days each. It seems that the higher the frequency of published entries the more visitors I got, with some topics being more popular than others.
For example, after my entry on "The lost civilization of our past was not Atlantis," my site lost around 250 unique page requests--the only reason I can think of for the substantial decrease in traffic is the esoteric topic and the length of the entry.
- It appears that the smaller the blog entry the more traffic it generates, regardless of the topic.
However, the topic for these shorter entries was "Soccer," "Sony," and "Google," which are very popular terms, so it is a fair assumption that "popular" words will generate more traffic via search results--this is something to keep in mind if your intent is to drive traffic to your web site.
- The caveat I introduced above has to do with increasing trends in traffic and the number of new blog entries: it may seem obvious that the more blog entries I published, the more traffic they generated. However, this assumption may not be completely accurate. The data does seem to indicate, though, that there is a correlation of blog entries and traffic generated, but I cannot claim it is the only reason.
The confounding comes from the organic growth of the web, i.e., if I were to stop publishing new content, the traffic will likely keep increasing as more new web surfers pop up all over the world--this should almost be an axiom of traffic growth in the internet: any site that is indexed by search bots will experience an increase in web traffic (this has probably been researched, but I did not look it up). Moreover, RSS feed readers will likely find the site and add them to their databases thus increasing traffic to any site publishing an RSS feed.
- Finally, the trend line (in red) indicates an R2 value of .4398, which is not a very high value for a coefficient of determination, but the data does seem to indicate the existence of some type of correlation of blog entries and page requests, i.e., roughly 44% of the increase of traffic could be accounted for by the new blog entries.
We cannot forget, though, that R2 values can be subject to objection in any statistical study, and, in this particular case, the correlation may be affected by other variables not accounted for in the model.
Earnings vs. Blog Entries Analysis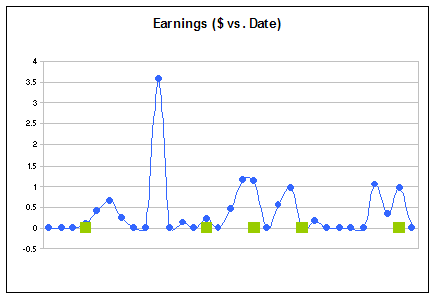
- If web surfers do not click on the ads, there are no revenues, thus, there were days with no earnings per day. However, some entries did generate more money than others.
For example, the period between "Pyramidal Paradigms" and "Code Reviewer == Code Editor?" (or February 26, 2006 to March 5, 2006) saw a healthy amount of money being made (this means web surfers are responding to the ads).
- There was not a clear increasing or decreasing trend in the amount of money being made, which is a direct result of the number of ad clicks per page.
- I appears that the more entries there were published, the more money was made--keep in mind, though, the confounding mentioned above: new entries may not be only reason people are visiting the site or are clicking on the ads.
- There was one particular date, March 1, 2006, that generated $3.58. This amount seems to be quite high, compared to the other days. The high value per click was probably due to the word associated with the to content being served that day.
Note the Clicks vs. Blog Entries chart below and look for the same date: there were as many clicks in other days, but the earnings per click were not as high as on March 1, 2006.
Like I said, not all words are worth the same amount of money, i.e., popular words will generate more click-thrus per page (for example "make money" vs. "panda tooth brush") and advertisers pay more to get their warez displayed on web sites and consequently making more money for the publishers when users follow the links.
Although, the converse is also true: it is less likely for anyone to write about "panda tooth brushes" on a blog, so advertisers have to pay google a higher premium for this scarce resource (blogs talking about tooth brushing pandas), i.e., it is all about the supply and demand of weird content.
Clicks vs. Blog Entries Analysis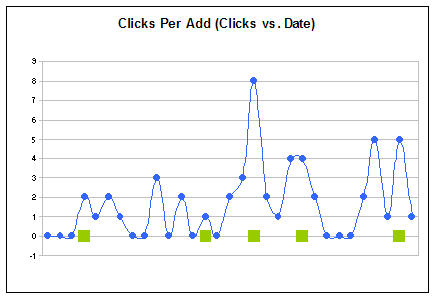
- There should not be any surprise that this chart resembles the same pattern of the Earnings vs. Date chart above, i.e., the more clicks the more money is made. However, I said that not all clicks are treated equally. This fact can be explored comparing both chart, so take a few moments to compare.
- Similar to the Earnings vs. Blog Entries chart, there does not seem to be a recognizable pattern of clicks per page.
All I can say is that it appears to be a random pattern, and that I really do not know why people click on ad links, but google is banking on the fact that association of keywords to content is one of the reasons.
It seems to be a good assumption, as their stock price attests. For example, assume you are surfing around and find a page about soccer and while reading such page you remember you need to buy soccer shoes: how likely are you to click on an add selling soccer shoes? Exactly. Who knows, but some of us may click on such ads.
Is there a probability model that can be used to predict how much money a blog could make depending on the traffic per day? Perhaps a Poisson distribution would aid, but expanding on this is out of the scope of my analysis.
Conclusions- Blogging seems to be profitable, and the amount of money you make is directly proportional to he amount of traffic your site generates.
- Fresh content seems to generate new traffic.
- Blogging is important in this money making equation because, currently, it is the only way to publish new content on web sites (I do not count RSS feeds, as it a way of automatically blog without putting any effort into it; and I discard news sites, as their job is to publish new content daily).
- If you blog, the shorter the entries the better your ads are likely to perform, i.e., people quickly read what you have to say and go on to the next link--advertisers count on the short attention span of web users to catch fast clicking fingers while the context of blog entries are in users' minds.
- The more popular your blog's theme is, the more traffic your site will generate, i.e., you will eventually create a web audience for your writing, which greatly accounts for repeat visitors.
You have to be cautious of anything having statistics and summaries presented to you as graphs: you always need to ask about the sampled data and the methodology followed throughout the experiment. So, keep in mind that these conclusions have been drawn from one study and one set of data. However, my blog is just as typical as any other, among millions, so the conclusions I have drawn have a certain validity across the board.
To truly make a serious statistical analysis, I would need more than 31 days worth of data, and, most importantly, I would need to make a cross-sectional analysis of different type of blogs, i.e., blogs that concentrate on politics, arts, video games, etc., etc. (This is something I am considering, given time and resources.)
Social ImplicationsEven though blogging can be used to generate money through advertising, the whole blogging phenomenon was not envisioned by genius capitalists trying to make a buck out of so much free content. Blogs, at least the coinage of the term, were a purely accidental phenomenon that took roots because of the availability of computers everywhere and cheap internet connections.
Many argue, as do I, that blogs are a way to disperse information to anyone who is interested and has the time to read them. Even though the information you find on the web may not be useful, well written, accurate, complete, or free of paranoic tendencies, the fact that it is available makes it one of the great achievements of our societies. At least for now, it seems to be an uncensored peek into many minds around some parts of the world.
So, if you have a blog, do not compromise on a topic or set of keywords to generate the most money from these advertising programs. Write as you will, I say, and if your content is interesting enough, you will find a web audience.
As I wrote in the beginning of this entry, all I wanted was to find out how much each word in my blog was worth. Apparently, not that much: $0.002681798. But it is all about the journey, in this case the analysis, and not just about the results.
(See the
graphs together and draw your own conclusions.)
Efficient Financial Markets and Google Application
Tuesday, March 21, 2006
Working my way through a Master of Business Administration (MBA), at
Wilfrid Laurier University, has made me a bit more sensitive to financial news and a bit more curious about all those interest rate hikes (Greenspan was a genius).
Aside from reading a million pages every week, as part of our training, we (the grad students) perform various financial analysis on different companies to get graded on the results. We also do the typical financial student thingy: finding out the Cost of Capital (WACC) for capital budgeting matters, figuring out required rates of return for equities (CAPM), calculating different financial ratios, finding market betas of different industries, study portfolio theory, etc., etc.
Most importantly, as future captains of industry*, we are inculcated that first world economy markets are said to be "efficient."
Efficiency in this context means that the market responds quickly to publicly available information. By "market" I mean the equity market or stock market; by "respond quickly to publicly available information" I mean that the price of a share is representative or valued depending on the information available at the moment of a trade--no more, no less. (Think of Nortel's share prices tanking when it was reported that they under-reported earnings a couple of years ago--the market reacted to the news and the stock price dropped rather quickly.)
So, why am I blabbering about this?
Well, google released a web application called Google Finance (finance.google.com and it's on beta of course), which makes use of the fact I just outlined above: the price of a share is dependent on the information available to the public.
With this web app, google once again shows its shareholders where all that money in R&D is going to: clean designed Flash applications that actually work.
Check this out (note the letters in the little squares):
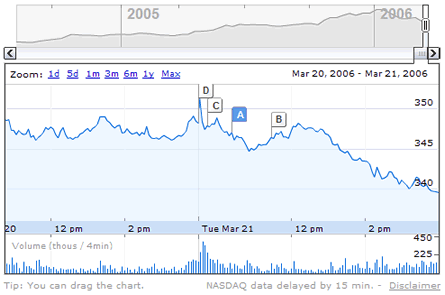
Ok, plotting graphs is not that impressive (everyone and their dogs can do it if you have the raw data). What's really cool and the connection to freely available information is this:
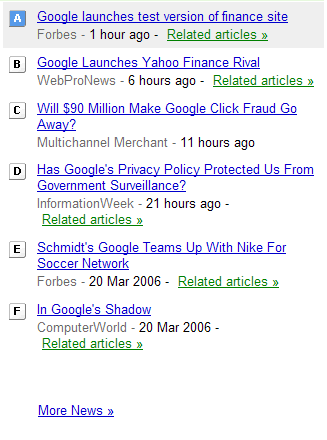
If you noted the letters inside the squares, you'll see what they are and how they are used: they are links to news that were published on that particular day. For example, you can see how the price of google's shares were related to the news of the day. You can also slide around the graphs and see the peaks and valleys, and the news section changes depending on the period displayed in the graph (cool
AJAX trick).
Pretty cool stuff and quite useful to Financial Analyst (and of course, for the amateur investor or business student). However, will news sites ever tell google to stop using their content for its own purpose?
At some point, I think they will.
I'm also predicting google will buy or license "real life" and index everything we do in their massive server farms. Gone will be days of you forgetting to pick up your kids from soccer practice: google will have an RSS feed reminding you on your cerebral google implant.
If it's information google can and will index it...And display ads through out...By the way, did you click on the google ads to your right? ;)
If you don't want to commit to going to finance.google.com, I have a
local screen grab of what the whole search result for google looks like (man, there's a lot of information available in that page).
* Note that an MBA is probably not the most direct path to become a "captain of industry." In my class, there are about as many reasons for getting a Master's degree as there are students. Are there any captains of industry amongst us? Only time will tell, however my mention of it at the beginning of this post shouldn't be taken too seriously--my head is quite small and we need to learn to not take ourselves too seriously.
How to lose market share (the Sony way)
Yet again, Sony is
delaying the PS3 release giving Microsoft an opportunity to gain market share.
Will this new move create another legal problem for Microsoft, a la XBox monopoly? I doubt it, but you just never know what the anti-monopoly police will say when everyone and their dogs will own an XBox and poor old PS3 and Nintendo machines are nothing but an after thought.
Sony really dropped the ball on this one.
I don't work for either company and I understand that developing and releasing a product on time to a hungry market is quite difficult, but we sure expected more from Sony, didn't we? Didn't we?
Microsoft's marketing models seem to work all the time: release a somewhat buggy product and loose a bit of money per unit in the process, but assure supremacy in a technology and software market.
The question is not "where do you want to go today," (as Microsoft's tag line used to be) the question is "how good enough is good enough for you to go where you think you want to go today."
Microsoft understands software development really well: there is no such thing as perfect software, so they let the market decide how many bugs and security holes it takes to turn off customers. Apparently, they haven't reached the limit. I like XP and
IE7, even with all their bugs. And so do all the millions of loyal Micro$oft costumers.
Football - Soccer - Futbol
Monday, March 13, 2006

Getting kicked in the shins hurts. Now imagine getting kicked with shoes with studs and with enough force to make a soccer ball travel at 70 mph. Trust me, it really hurts.
(Luckily there are only a few players in the world that can kick a ball that hard and maintain full control: Roberto Carlos from Brasil being one of them.)
Soccer shoes play an important role in the world's soccer market, to the point of paying professional players multi-million dollar shoe endorsement deals. With so much money being spent in designing and pimping these shoes around, does it really make a difference what type of shoe is used while playing the beautiful game?
Apparently someone did an ANOVA study to find out (ANOVA is a fancy acronym statisticians use to describe the process of studing different data sets and compare the difference between them):
When compared with the extensive research for running footwear, the biomechanical properties of soccer cleats have received little scientific attention. Only recently, players, organizations and shoe manufacturers became more interested in modern concepts of athletic footwear design for soccer cleats.
Prevention of injuries and performance enhancement are the key factors for any athletic footwear design. Shooting performance with five different soccer cleat constructions was evaluated, using methods for the measurement of ball speed, shoe deformation and tibial shock. The results of the study demonstrated the benefit of biomechanical analyses for the improvement of athletic footwear.
For ball speeds, the subjects showed low intra-individual coefficients of variation of less than 2% during the repetitive trials for a given shoe. This high repeatability in shooting performance of the individual players is a good basis for detecting statistical between shoe differences. Using an ANOVA (ANalysis Of VAriance between groups), significant between shoe differences were found for maximum ball speed, peak outsole deformation , peak outsole deformation velocity, and shock to the body.
Considering the concept of energy return, one might expect higher ball velocities with an increase of shoe deformation and/or shoe deformation velocity. However, one shoe model showed an opposite behavior. A regression analysis revealed low determination coefficients between ball speed and outsole deformation (r²=0.11) as well as outsole deformation velocity (r²=0.04). Similarly, low determination coefficients were also found for peak tibial acceleration against ball velocity (r²=0.04) as well as outsole deformation (r²=0.04).
[Note: these r² values are so low, that one can almost conclude that there is no statistically significan evidence of any difference in the type of shoe used. However, in some cases r² can be argued either way.]
The study demonstrated that ball velocity and shock transmission to the body is influenced by shoe construction features. For a variety of different cleat constructions, no trend could be found, relating the deformation of the soccer cleat to ball speeds. For a better understanding of the underlying mechanisms, a future study should investigate identical shoes, only differing in the stiffness of their outsoles.
Apparently, it makes a bit of difference in how you kick the ball depending on the type of shoes you wear.
What type of shoe do I wear? For me it's all about support and anti-pronation technology--after a nasty ankle injury my sport's Dr. told me I needed to switch shoes and get custom orthodics. I switched the shoes, but I stopped at the orthodics and I now wear ankle braces on both my feet. Wearing braces makes you loose a bit of ball control, however those ankles are locked--it's a good compromise, as getting sidelined for weeks at a time with a painful ankle injury really, really sucks.
BTW, I still think Brasil is going to win the World Cup. Go Brasil...
BTW2,
Craig Johnston invented those weird looking Adidas Predators. What was he thinking? And now he has a brand new design that makes the shoes look like gladiator boots. The new shoe is called "The Pig":

The lost civilization of our past was not Atlantis
Thursday, March 09, 2006
What should be the standard of measure of a highly evolved society?
To me, the fact that I just microwaved a full meal under 4 minutes indicates that I have god-like powers (hmm...Instantaneous food); for others, perhaps super-heating a gas to
3.6 billion degrees Fahrenheit is a good indication that our civilization is at the bleeding edge of technology--all I can say about this is "holly crap, isn't this dangerous?"; for our ancestors, it seems that building large monuments gave them the nod of being highly civilized people.
Last week, I bought the book
Fingerprints of the Gods, by
Graham Hancock. If you are like me, any book with the word "God" in the title jeers my skepticism radar a bit. Regardless, I bought it and read it and enjoyed it.
Fingerprints is an interesting narration of an old theory of a super-advanced ancient civilization spreading a legacy of fantastic acts and tales all over the world.
These past civilization, we are told, was the one who built the pyramids that have been sporadically and randomly spread in the jungles of America, a couple of dry regions in Egypt, and every other continent.
Hancock claims that the similarities found in archeological sites around the world are not coincidental at all, but are the result of a weird mission of a knowledge-spreading "white bearded man" civilization with super powers. This bearded-man, the native legends go, visited America's Incas in Peru, the Mayas in Central America, and the Aztecs in Mexico--way before Columbus officially "discovered" America.
The Incas called this "god-like" man "Viracocha," the Aztec called him "Quetzatcoatl," and the Egyptians call him "Osiris."
His purpose was always the same: to teach them everything about agriculture and living in peace, and, lets not forget, how to build humongous dirt and stone pyramids.
Hancock tried, in 1996, to give a different answer to the old question of why these monuments of grand scale were necessary. He wanted us to consider the alternative answer that these monuments were not just tombs for kings, but computers used to calculate and predict the end of the world--which is, by the way, December 23, 2012. I don't mean to be an alarmist here, but are you ready?
The proof of existence of this god-like civilization is speculatory at best, and none to be found anywhere at worst. Consider for example Chapter 22, where he talks about the City of the Gods, in Teotihuacan, as being built to represent a model scale of our solar system, including all nine planets--even
Pluto, which was only discovered a few years ago. If you don't believe me, check this out:


Along the same lines, one Engineer claims that the main city street was flooded with water and from the top of the pyramids you could see the water rippling through and this was used to tell different cataclysms around the world--I have to admit that this is a bit much, but is it pure coincidence that the site's structures perfectly depict the solar system? To this day, no one really knows why the city was built.
(About the rippling river of the City of Gods: remember Jurassic park and the scene with the cup of water and the running T-Rex--well, it is similar but think of the cup being a very large cup, and not a cup at all, but an artificial river surrounded by eerie looking pyramids. I'm guessing peyote was used at some point of the ordeal.)
What is extraordinary about these claims is that all these accomplishments of architecture and astronomy came from a civilization that, supposedly, existed 10,000 years ago (right around the last ice age).
I am gullible, so all these fantastic "coincidences" do not sound like coincidences at all.
However, I have one big "IF" about the whole thing...
It is a given that the people who built these monuments were quite gifted in all sorts of sciences, including politics, architecture, engineering, and mathematics--otherwise, they would have not been able to coordinate so much raw materials and human resources--but, why I wondered, would they build these massive stone and dirt computers to do something we can now do with a silicon chip the size pin head?
You may logically counter that these monuments do not need electricity and that they will outlive most of us. True, but why create such big stone computers? Why not a "laptop" stile stone-computer? (Maybe I have to look at the
Maya Calendar for that.)
Another question of mine: why is it that they didn't develop into an information society, the way our current civilization did in only 2,000 years?
Technological advances have quite a slippery and steep slope: once you start riding it, you can't escape it--look at what we have accomplished in the last 30 years.
What were the limitations these "advanced" societies of 10,000 years ago encountered that did not allow them to produce the overall advances that we have as a global society now a days? Why didn't they invent google, or the internet, or atomic bombs?
Perhaps they didn't have enough people with enough free time, as we do now, to invent seemingly useless crap (Napster, for example, wasn't so useless once you went beyond the copyright infringement thingy). Overpopulation has its benefits, so it seems; and maybe reading and writing for the average Joe may have done wonders for our current state of affairs.
The legends do cite these "white bearded men" arriving to these lands (and others) via "floating" or "flying shiny serpents"; or that 100 tons of solid rock were lifted and moved around the air with the aid of a whistle; or that these demi-gods could make the sky spit fire on command.
If these legends are true, then this Viracocha race did have the sort of technology we will have in 50 years from now. Hell, I can even say the technology we currently have: flying mechanical birds, speed boats, missiles, laser guns, picture taking phones, iPods, etc., etc.
I mention all these things because most of their construction or usage depend on electricity, opposite to the old monument-computers that didn't require anything to function except the right mathematical development (and we've only reach that level after 5,000 years of written history).
I wonder if this god-like race discovered and used electricity? I mean, an electron has been an electron, and will probably still be an electron billions of years from now. So I think it a fair question to ask, when legends are telling us that they could make crap fly around by the mighty power of a whistle. It is hardly a big stretch of the imagination to suggest they understood a bit of the fundamental components of matter and that electrons are negatively charged and could be transferred and channeled to do stuff. (I get that the allusion to a "whistle" is probably to something related to an anti-gravity instrument--but whistle just sounds funny.)
Why wouldn't these benevolent race give all these "secrets" to the semi-nude savages? (As opposed to just showing off). And why would they keep them in the dark about their origins? Why so many myths? Why allow them to carve rocks depicting their awesome powers? One thing is for sure, deities seem to like to be venerated.
My biggest question is why make them toil for decades at a time without any real benefit to them, except the realization of a job well done?
I have so many questions...
In the mean time, I can only imagine the equivalent of a present me, say "Jose Viracocha," in 2005 B.C. saying to himself: "My back hurts and I'm hungry, but this white bearded-god-man says we need to build this pyramid, and pronto. So I will work for corn and pray to him for more excruciating pain for another, what, 30 years more...By the way, this rock and dirt pyramid is turning out beautiful--I don't know what it is for, but I'm sure glad I'm a part of it."
Unless of course Viracocha/Quetzalcoatl/Osiris was indeed a god or an alien, I don't really see the point of forcing or "divinely persuading" thousands and thousands of an illiterate population to keep constructing these monuments as markers of past and future catastrophes.
(But, just in case they were gods and are still returning as they promised every race they visited, I don't want to sound irreverent, so if they are reading I personally welcome our Viracocha overloads--and most importantly, where do I sign up for forced pyramid building labour? I loves to build me one of them tombs...)
On a serious note, the book is very entertaining and gives you this guilty pleasure of being initiated into a secret that only few know (well, at least the thousands and thousands who have bought the book and now the three of you reading this web site). The claims are so extraordinary, I sometimes forgot I was reading about "real" events and real places, but the few math references appealed to my geeky side so I enjoyed the tales and archeological detective work.
The big secret and summary of the book, in a nutshell (sorry for the spoiler): there was once a civilization so great, composed of men (and women, I supposed--weird, women never show up on most of this ancient myths) who knew everything about the roundness of the Earth, that understood the phenomenon of the Earth's precession and how it relates to the seasonal changes. Moreover, this super advanced raze may have lived in Antartica when the continent was not where it is right now, but was around equatorial latitudes and it is where it is now because of some cataclysmic Earth crust movement, and finally, they (the demi-gods) decided to leave markers and computers in the forms of stone monuments so that we could understand what happened and will happen to the world.
To me, everything sounds feasible but there are those things that don't quite add up and we will probably never know why this math knowing and great architects built such large monuments with apparently no real use. Perhaps "never" is too strong of a word, but archeologist and linguist will have to get their act together to figure these things out (if not them, then who).
There are claims that there was actually a written history left by the Mayas and Aztecs about this lost civilization, but everything that was not carved in stone was mostly burnt and destroyed at the time of the conquest by eager Catholic priests and Spanish conquistadors.
In truth, we can use numbers to associate anything to anything if we really wanted to. So a problem I have is that we are trying to retrofit our current knowledge to these old monuments with the aid of mathematics. However, if indeed these 10,000 year old undiscovered civilization knew then all we know now, they were indeed god-like Viracocha/Quetzatcoatl/Osiris and deserve their tales to have been immortalized in pieces of rock.
By the way, I give
Fingerprints "4 great pyramids of Giza out of four," but if you read the book you must keep repeating to yourself "I want to believe...I want to believe...I want to belie..." Hey, isn't that the motto for the X-files? So that you know, I didn't like the X-files that much; I only saw a few episodes.
And to keep feeding the
fire, check this aerial view of Giza and Teotihuacan:

How is that for coincidental alignment of totally unrelated monuments?
Code reviewer == Code editor?
Sunday, March 05, 2006
dictionary.com defines "editor" as follows:
editor
n 1: a person responsible for the editorial aspects of publication; the person who determines the final content of a text (especially of a newspaper or magazine) [syn: editor in chief] 2: (computer science) a program designed to perform such editorial functions as rearrangement or modification or deletion of data [syn: editor program]
Editing seems to be all about quality, but not in the computer science sense. So how can we introduce editors into our Software Engineering practices?
Fancy Software Engineering books tell us that code reviews are part of the Quality Assurance process used to improve the quality of code, along the lines of controling the
variability of code.
I doubt anyone would argue against performing code reviews. They are a good thing, however, they are time consuming and sometimes redundant.
Code reviews can also become a liability if there is no clear goal to accomplish, or the whole process is faulty, i.e., it is performed in an ad-hoc manner, or for example, if your code reviews are only checking for style and variable-name consistency--in this case, you should save the time and effort it takes to perform them, and just invest in training your development group with the proper syntax and coding standards of your choice.
Code reviews should, in my view, be more of a dry run of the code to make sure everything gels. In other words,
a code reviewer should be the equivalent of an editor in the publishing business.
An editor will try to fix everything on any piece of written work before hitting the printing press (they try, at least). The code reviewer's job, then, should be to find faults in logic, syntax, performance, and try to make a piece of code as elegant and efficient as possible (yes, code should be elegant) before formally transitioning the component to the Quality Assurance group, and after unit testing has been completed by the developer.
In other words, a code reviewer/editor should start eyeing the code files when the code tree fully compiles and has passed the minimum developer's test suits.
Reason would dictate that by adding one more layer to development life cycle, you are adding more time to your timelines therefore exploding your budgets, however, this is fact not the case when you look at the development cycle as whole, i.e., Software Engineering/Development is not just programming.
Fixing problems when QA finds them is actually more expensive than fixing them when the developer is still playing around with lines of code, i.e., a full cycle of development/formal testing can get quite expensive in the long run.
Formalized code review cycles, however, are sometimes unrealistic. For example: there may not be anyone on the team that can do a good job at it; or the budget is extremely tight and there is really no money left to review all the code; or, lets face it, reviewing 100,000 files per project is not feasable: assume it takes 3 hours to review each file. That is 300,000 hours, or 7,500 forty-hour weeks to review the code tree--this is quite an expensive proposition. Though, it is one of those things: damned if you do it, damned if you don't.
I would say you that should try to implement some type of code review at some point in your engineering process, and perhaps be selective and choose the files that contain complex algorithms.
To bring finances into the matter: if you think of code review as as waste of time, then you do not know about the time value of money. It is obvious that finding a bug and fixing it right now, is cheaper than finding one and fixing it tomorrow. (The time value of money stipulates that a dollar earned today is worth more than one earned tomorrow because of inflation and such.)
Introducing a "code editor" into the mix brings another interesting point: what if developers start relying too much on the editor to correct mistakes?
I guess if it comes to this, then a better software engineering process needs to be put in place since developers should not rely on extra resources to write quality code.